
月之暗面在6月12日正式端出了Kimi 2.7 Code,这并不是一次颠覆性的物种进化,而是一次极为务实的、针对AI编程场景的体系化打磨。
1. 技术去噪:从“追求参数”到“精算成本”
以往国内大模型升级,通稿里全是生涩的算法术语,而Kimi 2.7 Code这次扔出来的核心数据,却很有“工程味”和“账本思维”:长程任务中的过度思考(Overthinking)倾向被大幅改善,平均Token消耗生生减少了30%。
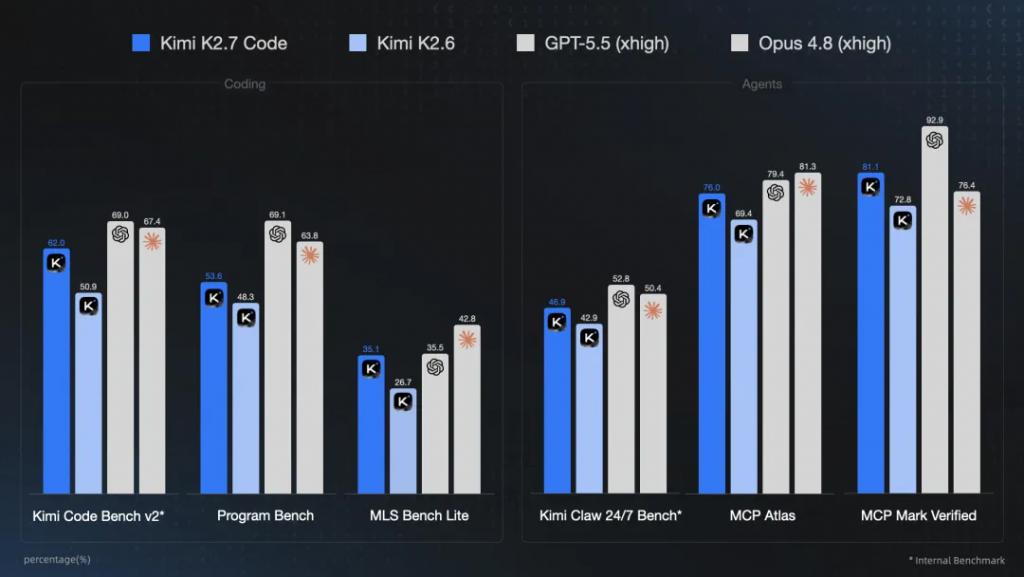
在硬核编程能力上,内部外基准测试的数据表现得很直观:Kimi Code Bench v2提升21.8%、Program-Bench提升11%,而MLS Bench Lite更是暴涨了31.5%。
模型底层代码能力的进化,带来的是上层Agentic(智能体)自主化执行能力的质变。在评估Agent能力的Kimi Claw 24/7 Bench、MCP Atlas和MCP Mark Verified基准测试中,其性能均有10%左右的斩获。这意味着,它在处理长上下文编程和复杂指令遵循时,不再是一个只会对单行代码修修补补的辅助工具,而是开始具备了更长周期的“全栈自主”品味。
2. 坦诚对比:中文AI的“脱虚向实”
如果说Kimi 2.7这次的发布稿有什么最让人神清气爽的地方,那就是月之暗面终于解绑了那种病态的“全能幻觉”。他们没有非得在某个精心雕琢的测试集里去超越当前的GPT-5.5或者Opus 4.8。甚至在内部测试中,他们坦然承认差距依然客观存在。
如果把大模型在编程领域的终极表现量化一下:GPT-5.5和Opus 4.8如果是70分的工业级标杆,那么前代的Kimi 2.6可能只有50分的及格边缘,而这次的Kimi 2.7 Code则是稳稳跨过了60分的实用门槛。
这种坦诚在当下极其稀缺。过去很多国内公司发布产品,喜欢找一两个偏门项目证明自己“超越硅谷巨头”,这种为了公关KPI而制造的繁荣,除了满足信息自嗨外没有任何商业价值。月之暗面这次的“不装了”,反而展现出了一种大厂才有的战略定力——我知道我的边界在哪,我只解决当下的用户痛点。
3. 以战养战:K3前的中场休整
必须明确的是,Kimi 2.7 Code只是K2系列的一次小版本“微调”。月之暗面在2026年真正的核武,依然是尚未揭下面纱的Kimi K3。按照官方此前透露的口风,K3才是一次底层架构级别的全面重构,届时国内AI才有机会真正去跟GPT-5.5和Opus 4.8在最高维度的战场上正面掰手腕。
而在K3到来之前,2.7 Code更像是用高性价比去稳固开发者基本盘的“护城河”产品:
- 无缝平替: 开发者今天就能直接调用,价格与K2.6完全持平,Code Plan计划默认无痛升级。
- 各司其职: K2.6并不会退役。官方甚至很清醒地建议,在非编程的通用文本任务中,全面性更好的K2.6依然是首选。
- 高频套利: 下周一(6月15日)还将上线高速版,输出速度直接狂飙5-6倍。在常规编程场景下,输出速度能达到180 Token/s,短上下文甚至能冲到260 Token/s。而代价,仅仅是极其良心的2倍定价。
科技的演进不应只有宏大叙事,更需要柴米油烟里的精打细算。Kimi 2.7 Code的发布证明了,国内AI巨头正在从“概念军备竞赛”走向“服务与性价比的持久战”。不盲目拼参数,转而帮开发者省下30%的Token账单,用5-6倍的极速去对冲开发者的等待焦虑。这种务实的进化,比任何虚妄的“降维打击”都更具商业杀伤力。

